 |
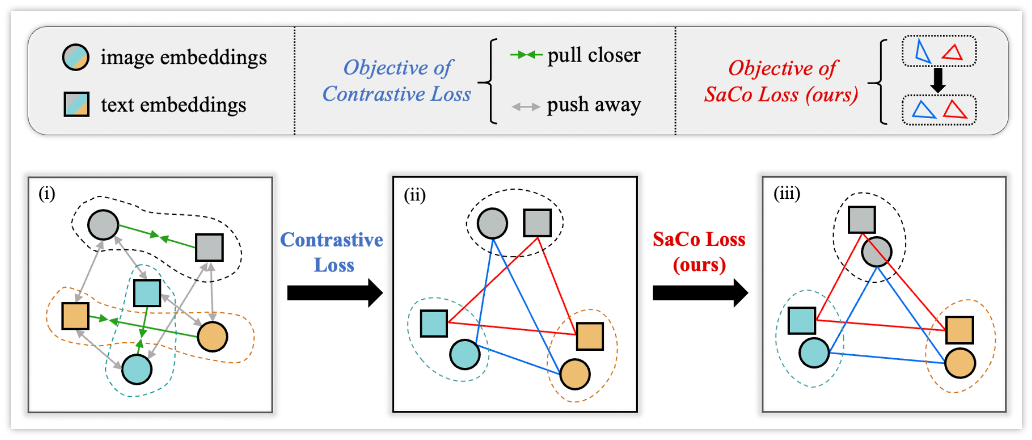
SaCo Loss: Sample-wise Affinity Consistency for Vision-Language Pre-training
Sitong Wu*, Haoru Tan*, Zhuotao Tian, Yukang Chen, Xiaojuan Qi, Jiaya Jia
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024
paper
|
 |
Data Pruning via Moving-one-Sample-out
Haoru Tan*, Sitong Wu*, Fei Du, Yukang Chen, Zhibin Wang, Fan Wang, Xiaojuan Qi
Conference on Neural Information Processing Systems (NeurIPS), 2023
arXiv code
|
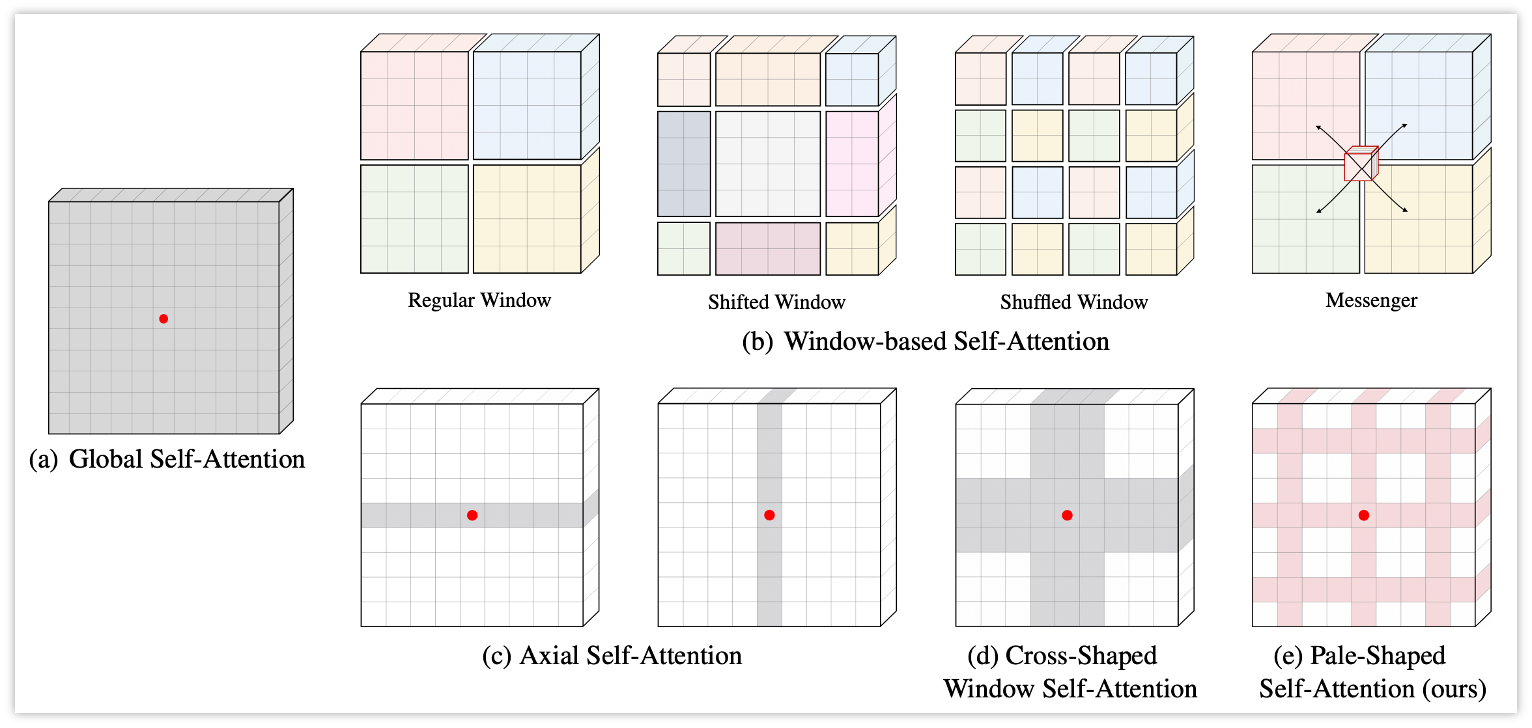 |
Pale Transformer: A General Vision Transformer Backbone with Pale-Shaped Attention
Sitong Wu, Tianyi Wu, Haoru Tan, Guodong Guo
Association for the Advancement of Artificial Intelligence (AAAI), 2022, Oral
paper arXiv code
|
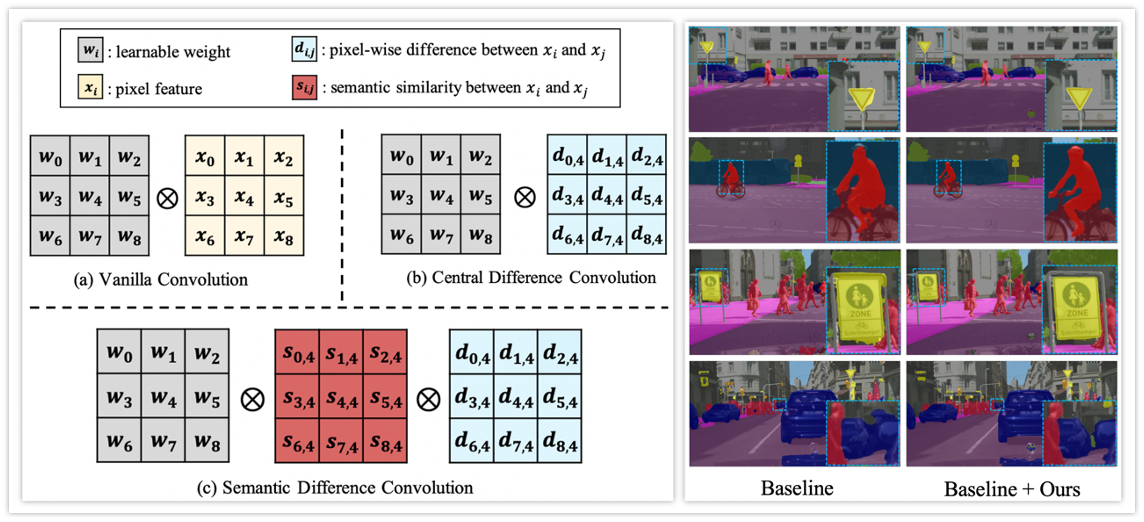 |
Semantic Diffusion Network for Semantic Segmentation
Haoru Tan*, Sitong Wu*, Jimin Pi
Conference on Neural Information Processing Systems (NeurIPS), 2022
paper arXiv code
|
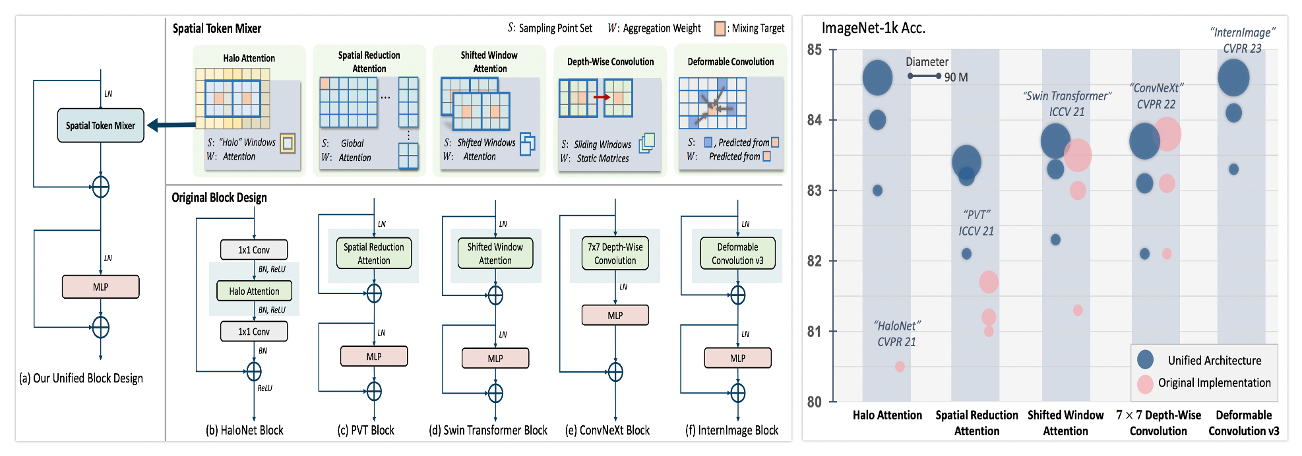 |
Demystify Transformers & Convolutions in Modern Image Deep Networks
Xiaowei Hu*, Min Shi*, Weiyun Wang*, Sitong Wu*, Linjie Xing, Wenhai Wang, Xizhou Zhu, Lewei Lu, Jie Zhou, Xiaogang Wang, Yu Qiao, Jifeng Dai
arXiv: 2211.05781
arXiv code
|
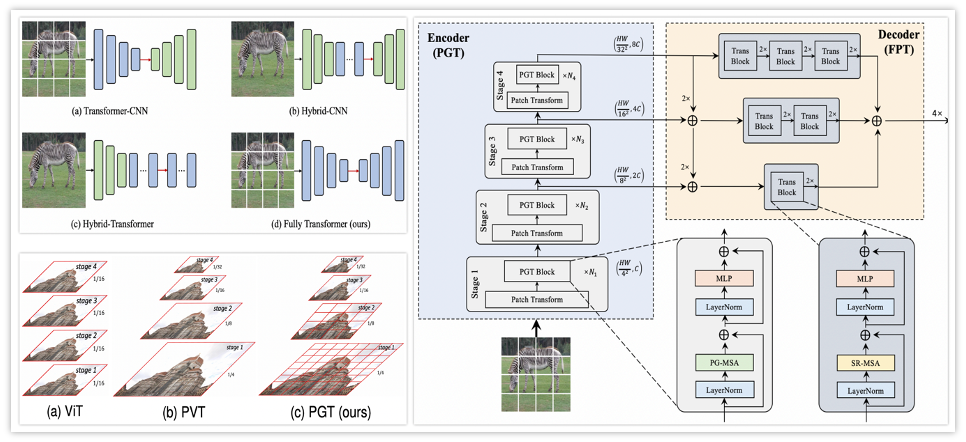 |
Fully Transformer Networks for Semantic Image Segmentation
Sitong Wu*, Tianyi Wu*, Fangjian Lin*, Shengwei Tian, Guodong Guo
arXiv: 2106.04108
arXiv code
|
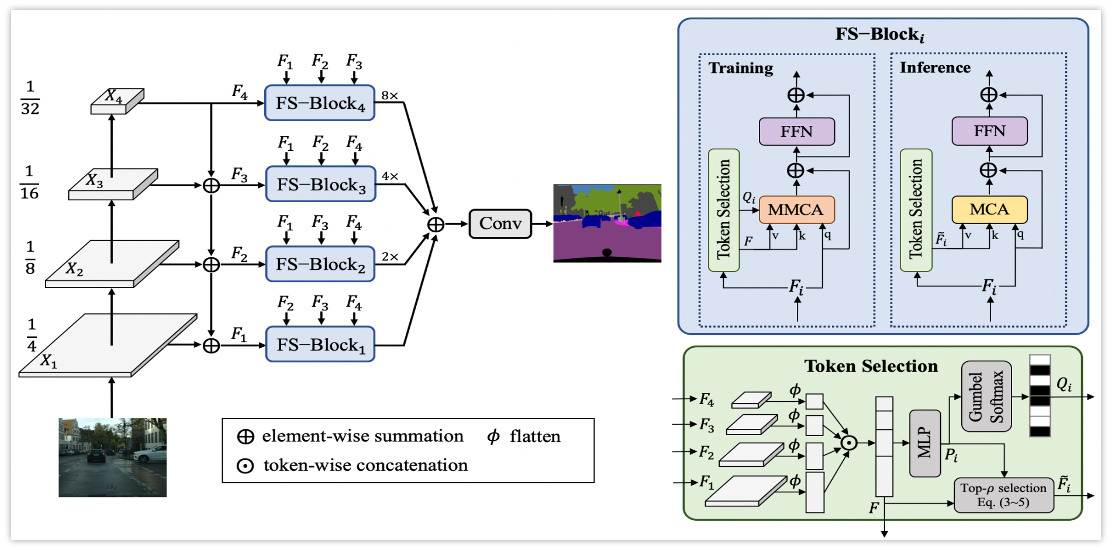 |
Full-scale Selective Transformer for Semantic Segmentation
Fangjian Lin*, Sitong Wu*, Yizhe Ma, Shengwei Tian
Asian Conference on Computer Vision (ACCV), 2022
paper
|
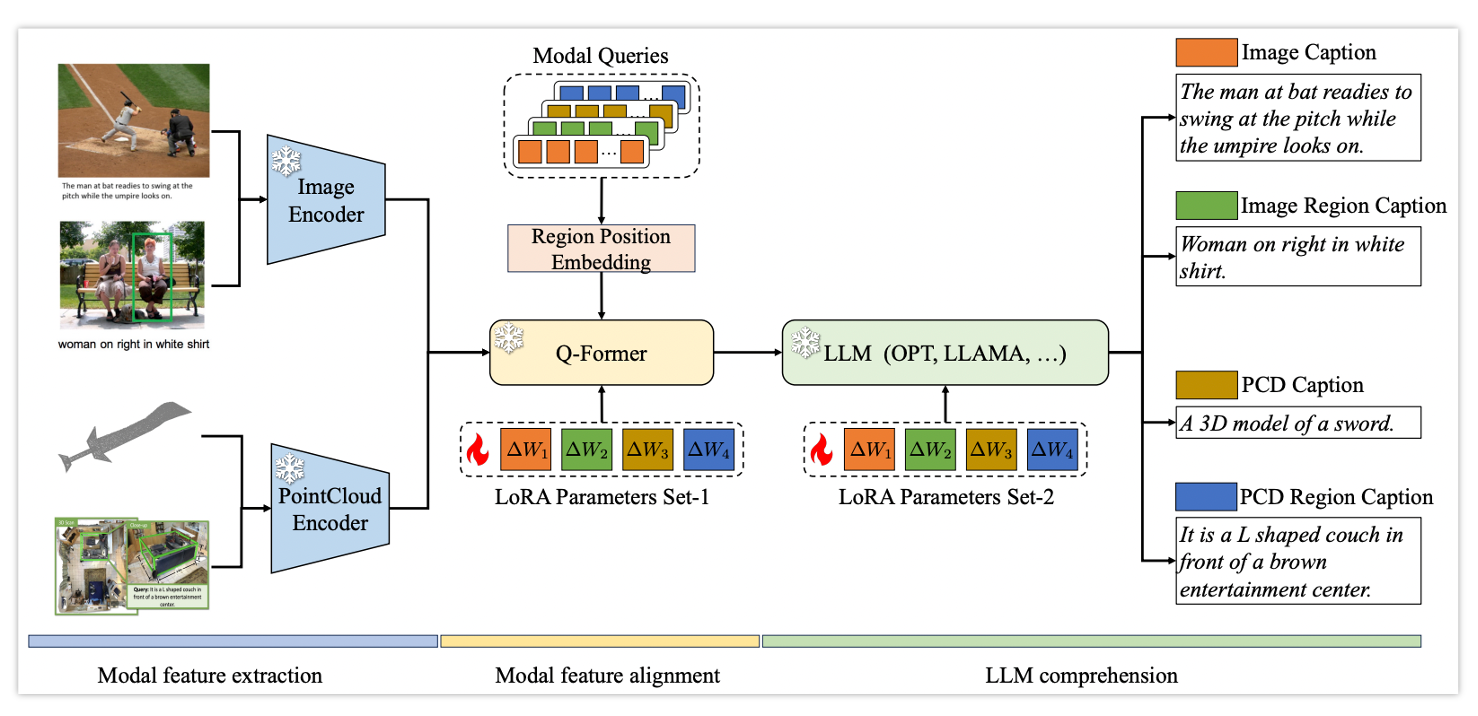 |
RegionBLIP: A Unified Multi-modal Pre-training Framework for Holistic and Regional Comprehension
Qiang Zhou, Chaohui Yu, Shaofeng Zhang, Sitong Wu, Zhibin Wang, Fan Wang
arXiv: 2308.02299
arXiv code
|
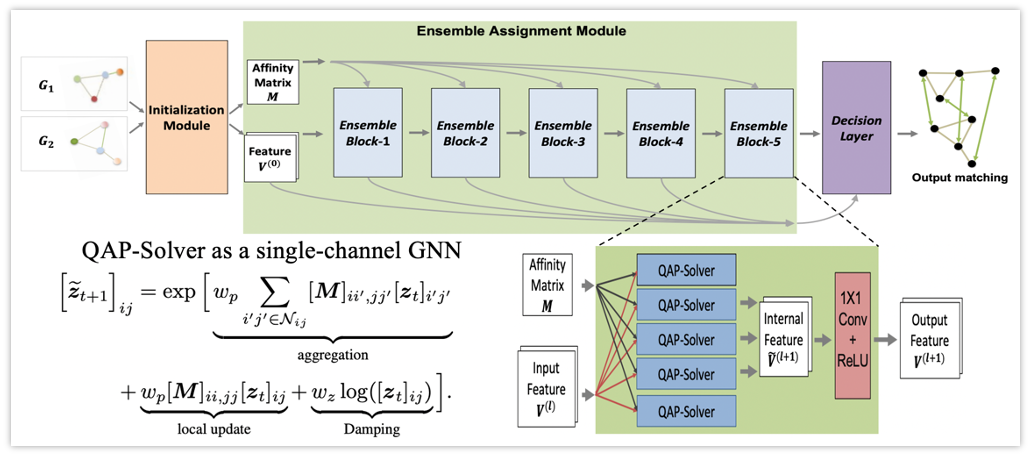 |
Ensemble Quadratic Assignment Network for Graph Matching
Haoru Tan, Chuang Wang, Sitong Wu, Xuyao Zhang, Fei Yin, Chenglin Liu
International Journal on Computer Vision (IJCV), 2024
arXiv
|
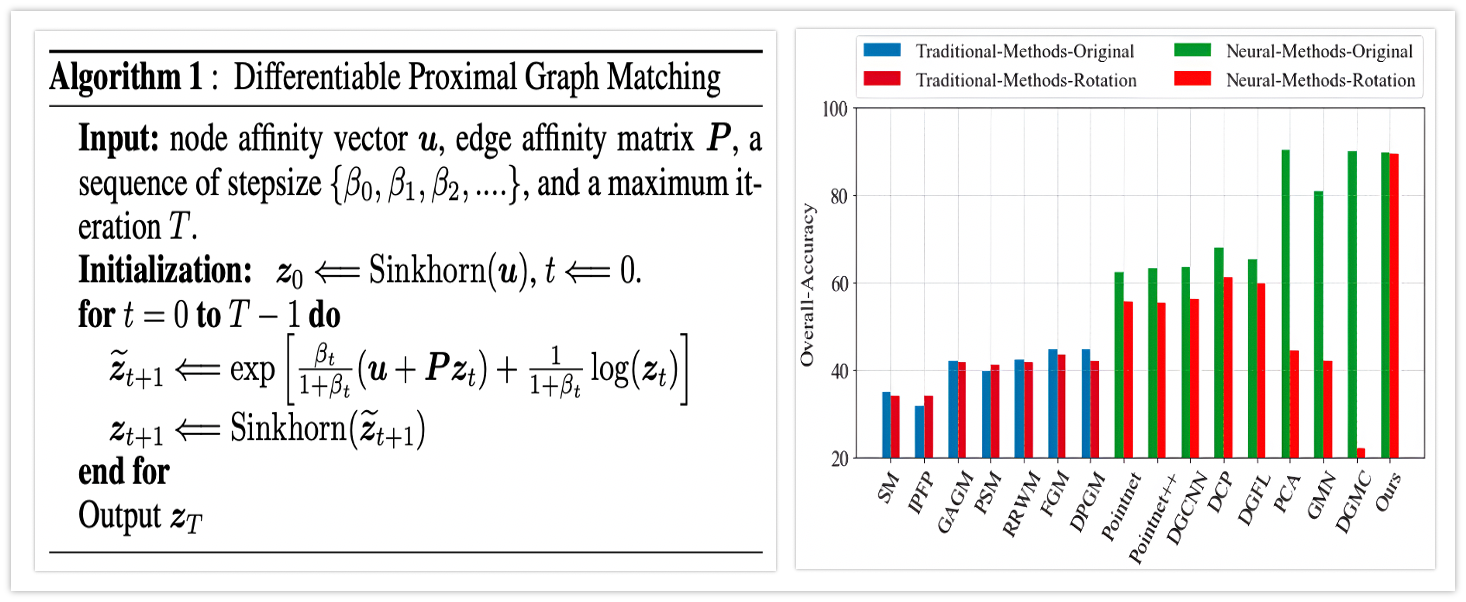 |
Proxy Graph Matching with Proximal Matching Networks
Haoru Tan, Chuang Wang, Sitong Wu, Tieqiang Wang, Xuyao Zhang, Chenglin Liu
Association for the Advancement of Artificial Intelligence (AAAI), 2021
paper
|
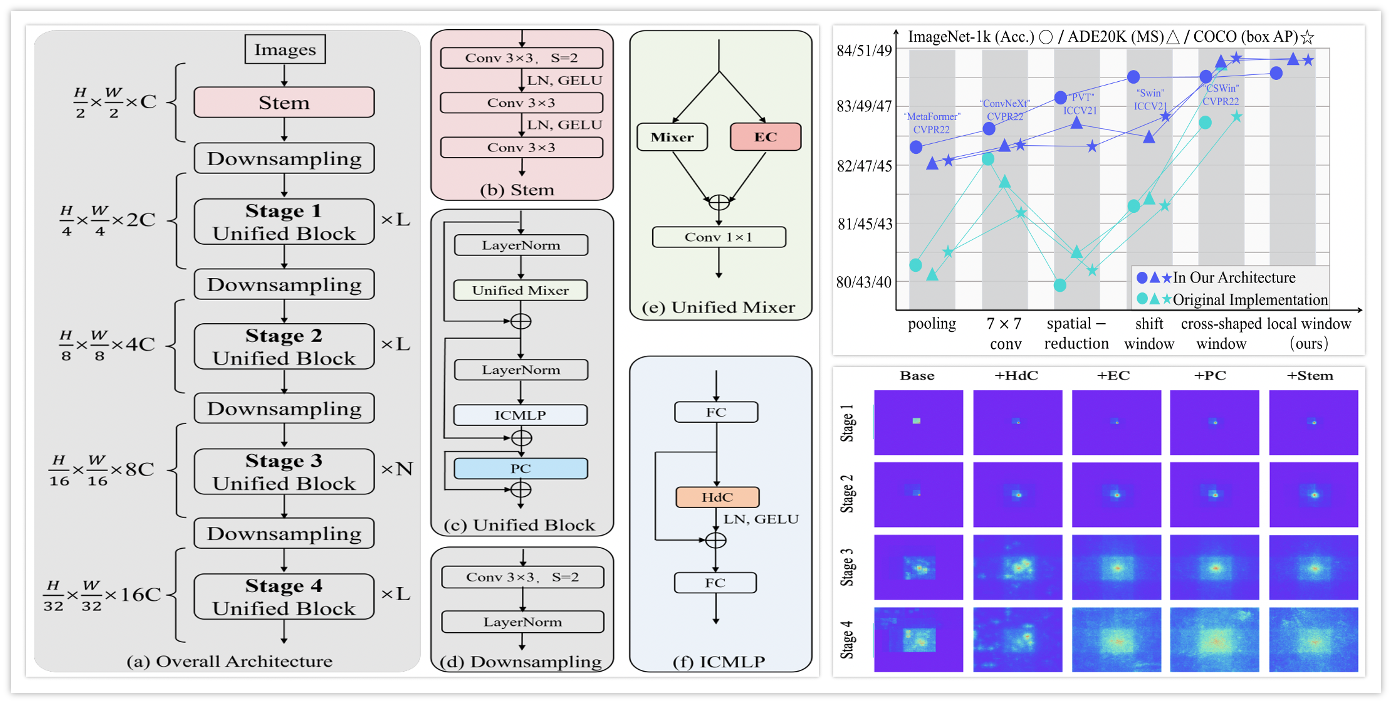 |
UniNeXt: Exploring A Unified Architecture for Vision Recognition
Fangjian Lin, Jianlong Yuan, Sitong Wu, Fan Wang, Zhibin Wang
ACM Multimedia Conference (ACM MM), 2023
paper arXiv code
|
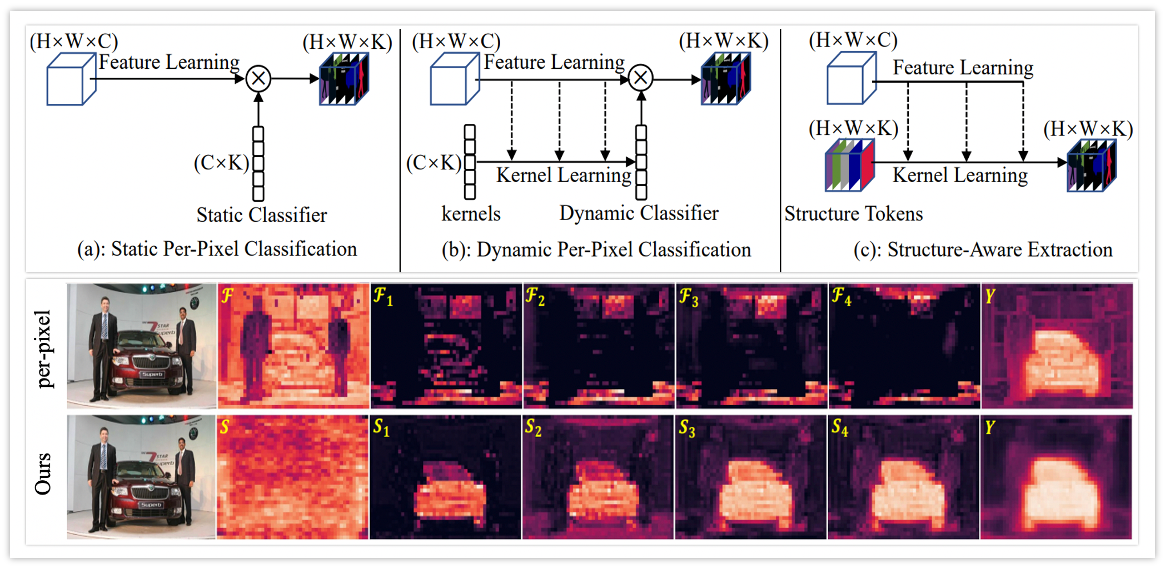 |
StructToken: Rethinking Semantic Segmentation with Structural Prior
Fangjian Lin*, Zhanhao Liang*, Sitong Wu, Junjun He, Kai Chen, Shengwei Tian
IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), 2023
paper arXiv code
|
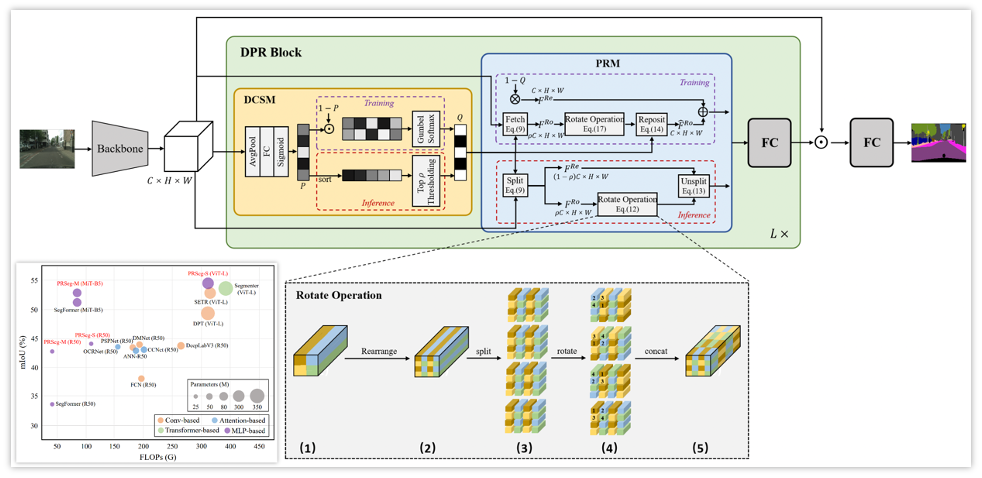 |
PRSeg: A Lightweight Patch Rotate MLP Decoder for Semantic Segmentation
Fangjian Lin*, Yizhe Ma*, Sitong Wu, Long Yu, Shengwei Tian
IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), 2023
paper arXiv
|
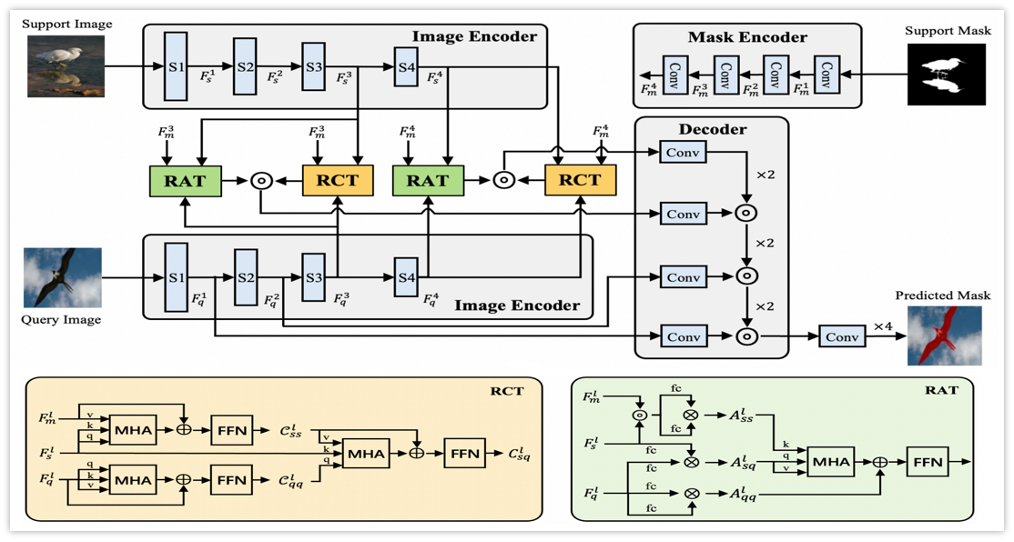 |
CATrans: Context and Affnity Transformer for Few-Shot Segmentation
Shan Zhang, Tianyi Wu, Sitong Wu, Guodong Guo
International Joint Conference on Artificial Intelligence (IJCAI), 2022
paper arXiv
|
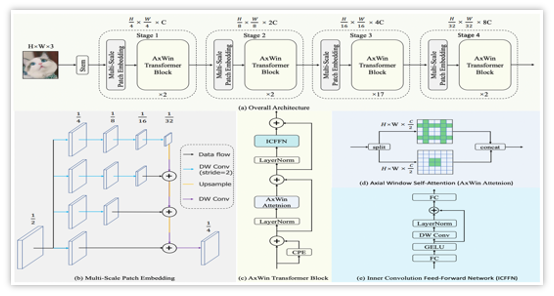 |
AxWin Transformer: A Context-Aware Vision Transformer Backbone with Axial Windows
Fangjian Lin, Yizhe Ma, Sitong Wu, Long Yu, Shengwei Tian
arXiv: 2305.01280
arXiv
|



